В статье мы рассмотрим один из случаев, с которым наши клиенты обращаются в техническую поддержку. Суть в следующем: на сервере крутится специфическое ПО, например, для обсчёта кубов данных, которое интенсивно работает с БД. В какой-то момент производительность ПО заметно снижается, под подозрение попадает дисковая подсистема сервера и клиент обращается в техподдержку Cloud4Y для соответствующей диагностики.
Проверка начинается с нашей - провайдера - стороны: инженеры анализируют общую нагрузку, в т.ч. на СХД и утилизацию указанной в тикете ВМ выделенных ей ресурсов. Когда становится понятно, что "снаружи" проблем нет - переходят к диагностике "изнутри" ВМ. Вот об этом далее и пойдёт речь.
Логика метода достаточно простая: провести пару раундов замеров, 1й под реальной рабочей нагрузкой, 2й - с и без тестовой нагрузки. Это позволит, во-первых, получить контрольные показатели iops при максимальной загрузке дисковой подсистемы тестами и на холостом ходе. А во-вторых, сравнить их с полученными рабочими метриками при реальной нагрузке.
С целью демонстрации метода диагностики был развёрнут тестовый стенд в виде виртуальной машины на базе Ubuntu 20.04 x64, 2 ядра CPU, 4 ГБ памяти, диск 30 ГБ с профилем vcd-type-med - ограничение в 1000 iops.
Стандартом индустрии для проверки iops в *nix системах является утилита iostat из пакета SYSSTAT, а нагрузочное тестирование выполняется с помощью утилиты fio - их необходимо установить:
sudo apt update
sudo apt install sysstat
sudo apt install fio
После установки проведите 1й раунд замеров при реальной нагрузке в течении, например, 10 минут:
iostat -x -t -o JSON 10 60 > "iostat-1.json"
Параметры iostat означают провести 60 замеров с интервалом 10 секунд, вывод в json-формате направить в файл iostat-<№_раунда>.json. Количество и интервалы вы можете выставить на свое усмотрение - в одном реальном случае мы снимали замеры на протяжении суток с почасовой разбивкой. Что касается json-формата, то его намного проще обработать в дальнейшем программно, чем парсить псевдотабличный вывод утилиты regexp'ами, но его поддержка есть только в достаточно свежих версиях - 12.x - и если у вас очень старая гостевая ОС, напр., Ubuntu 16.04 или ниже, вероятнее всего придётся собрать пакет из исходников.
Во 2м раунде выключите "боевую" нагрузку и включите измерения:
iostat -x -t -o JSON 10 60 > "iostat-2.json"
и несколько раз в течении 10 минут работы iostat включите тестовую нагрузку с помощью fio на 1-2 минуты:
fio --rate_iops=700,300, --bs=4k --rw=randrw --percentage_random=50 --rwmixread=70 --rwmixwrite=30 --direct=1 --iodepth=256 --time_based --group_reporting --name=iops-test-job --numjobs=1 --filename=runfio.sh.test --size=1GB --ioengine=libaio --runtime=60 --eta-newline=10
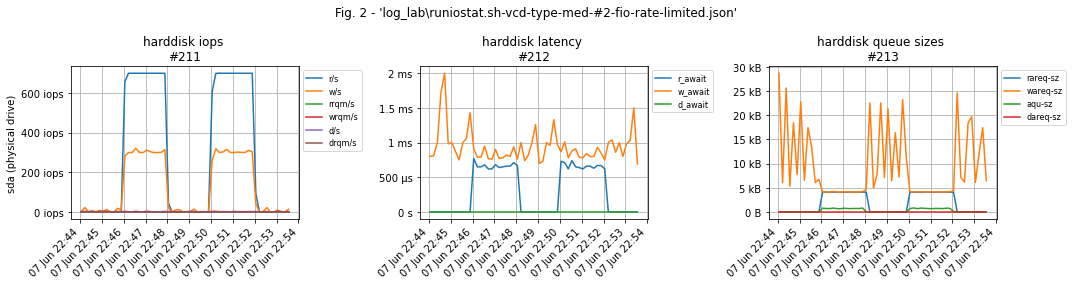
Параметр --rate_iops=700,300, указывается в формате --rate_iops=[read],[write],[trim] и означает "дать нагрузку 700 iops на чтение, 300 - на запись, значение trim оставить по умолчанию". Числа выбираются исходя из указанного в Cloud Director'е общего лимита iops на конкретный диск и распределения нагрузки 70% на чтение / 30% на запись. В случае тестового стенда общий лимит равен 1000 iops, поэтому нагрузка распределяется как 700/300.
Важный нюанс: если не ограничить нагрузку, то fio сгенерирует максимально возможное количество операций ввода-вывода, это приведёт к тому, что в тесте многократно возрастёт latency IO-операций виртуального диска из-за тротлинга vSphere'ой "лишних" операций: ВМ постоянно будет пытаться сделать iops больше положенного, а vSphere - будет подстраивать глубину очереди так, чтобы придержав "лишние" операции перед их отправкой СХД соблюсти ограничение.
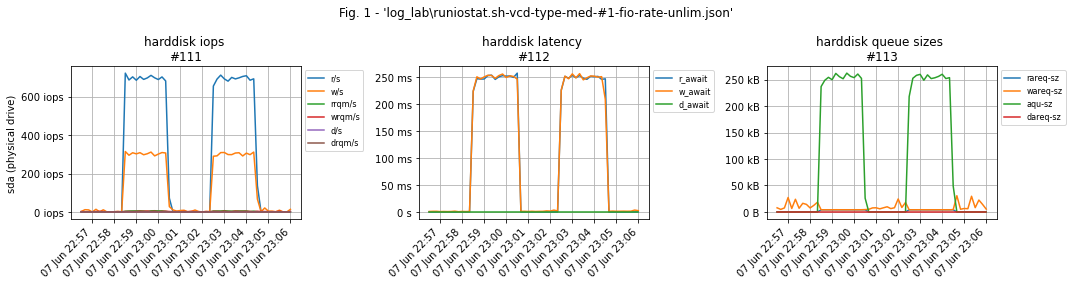
Оба теста подтверждают работоспособность диска на 1000 IO-операций, но в 1м случае, без --rate_iops=W,R, в замерах мы получим throttling latency, а во 2м - реальные значения.
Для проверки latency можно использовать отдельную утилиту ioping:
# установка
$ sudo apt-get install ioping
# проверка
$ ioping -c 9 /tmp/
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=1 time=309.1 us (warmup)
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=2 time=717.3 us
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=3 time=583.4 us
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=4 time=430.2 us
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=5 time=405.8 us
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=6 time=387.4 us
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=7 time=382.1 us (fast)
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=8 time=811.6 us (slow)
4 KiB <<< /tmp/ (ext4 /dev/sda5): request=9 time=706.9 us
--- /tmp/ (ext4 /dev/sda5) ioping statistics ---
8 requests completed in 4.42 ms, 32 KiB read, 1.81 k iops, 7.06 MiB/s
generated 9 requests in 8.00 s, 36 KiB, 1 iops, 4.50 KiB/s
min/avg/max/mdev = 382.1 us / 553.1 us / 811.6 us / 162.7 us
lsblk -f/ls -l /dev/mapper наглядно отразят структуру дисковой подсистемы вашей ВМ.Обработку и визуализацию json-файлов замеров мы выполнили на Python в среде JupyterLab при помощи библиотек pandas и matplotlib. Вы можете воспользоваться нашим "велосипедом", либо написать свой - для вас мы подготовили архив с исходниками и примером обработки замеров в виде - ipynb - jupiter-блокнота.
В конечном итоге по графикам вы сможете либо однозначно исключить дисковую подсистему из подозреваемых, либо заняться её оптимизацией или обосновано сменить дисковую политику на более производительную.
Пример графиков тестового стенда. Тестовая нагрузка на графиках выглядит как два "верблюжьих горба": 700 iops на чтение и 300 - на запись. Графиков рабочей нагрузки по понятным причинам нет.
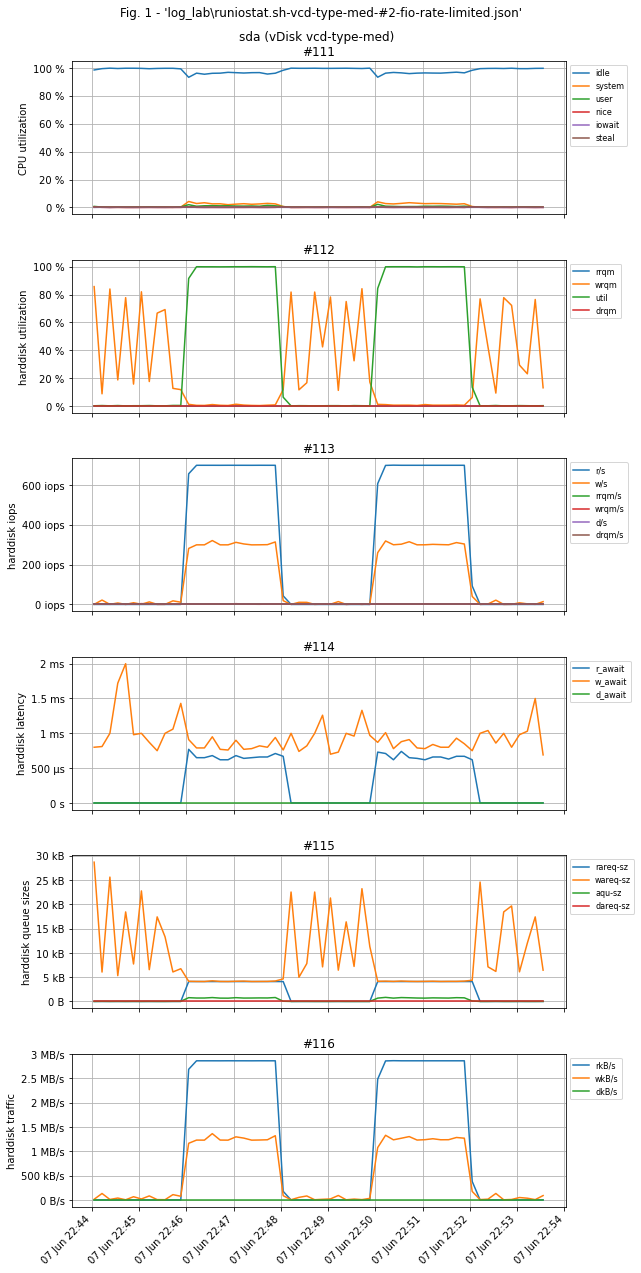
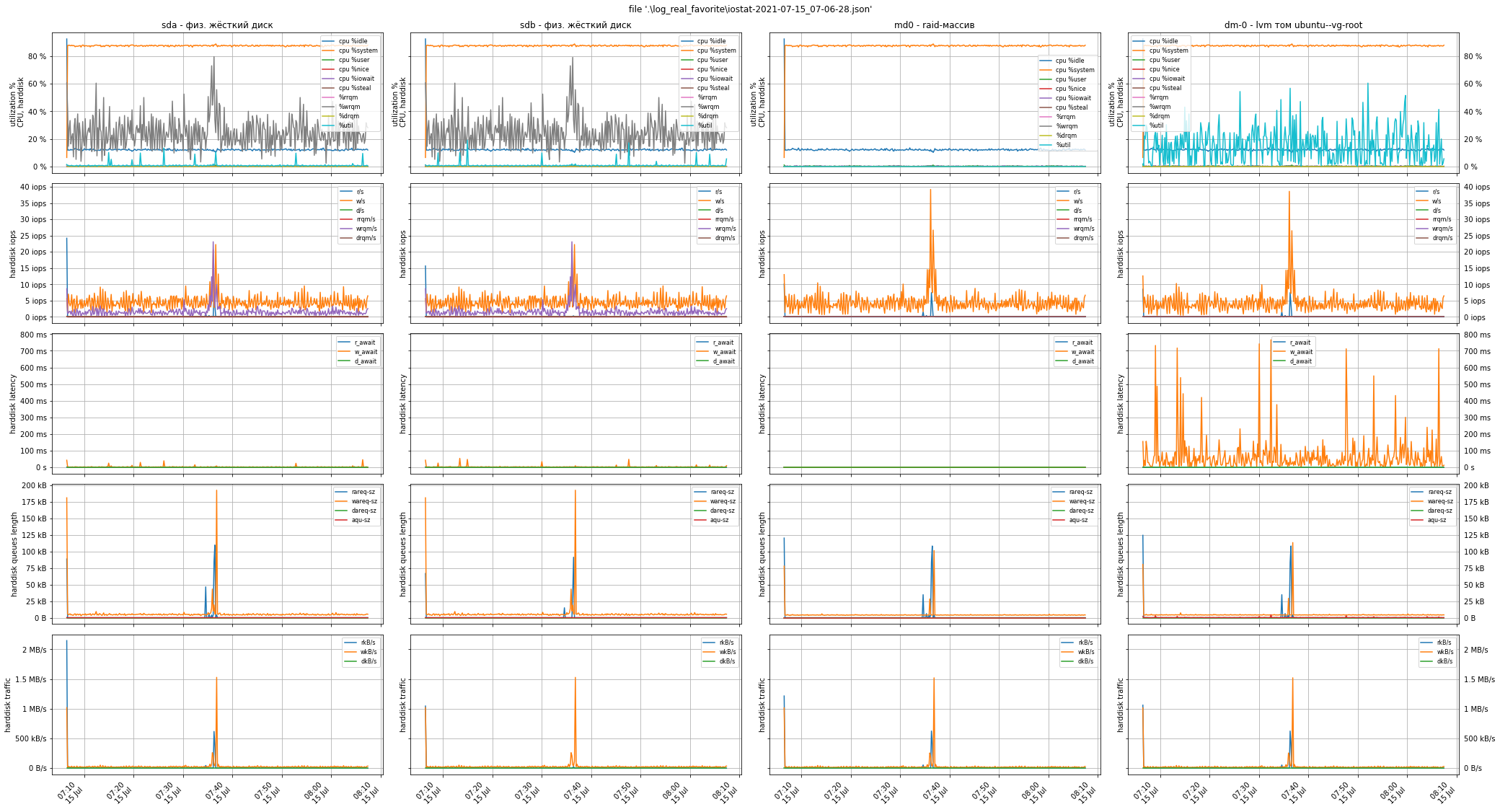
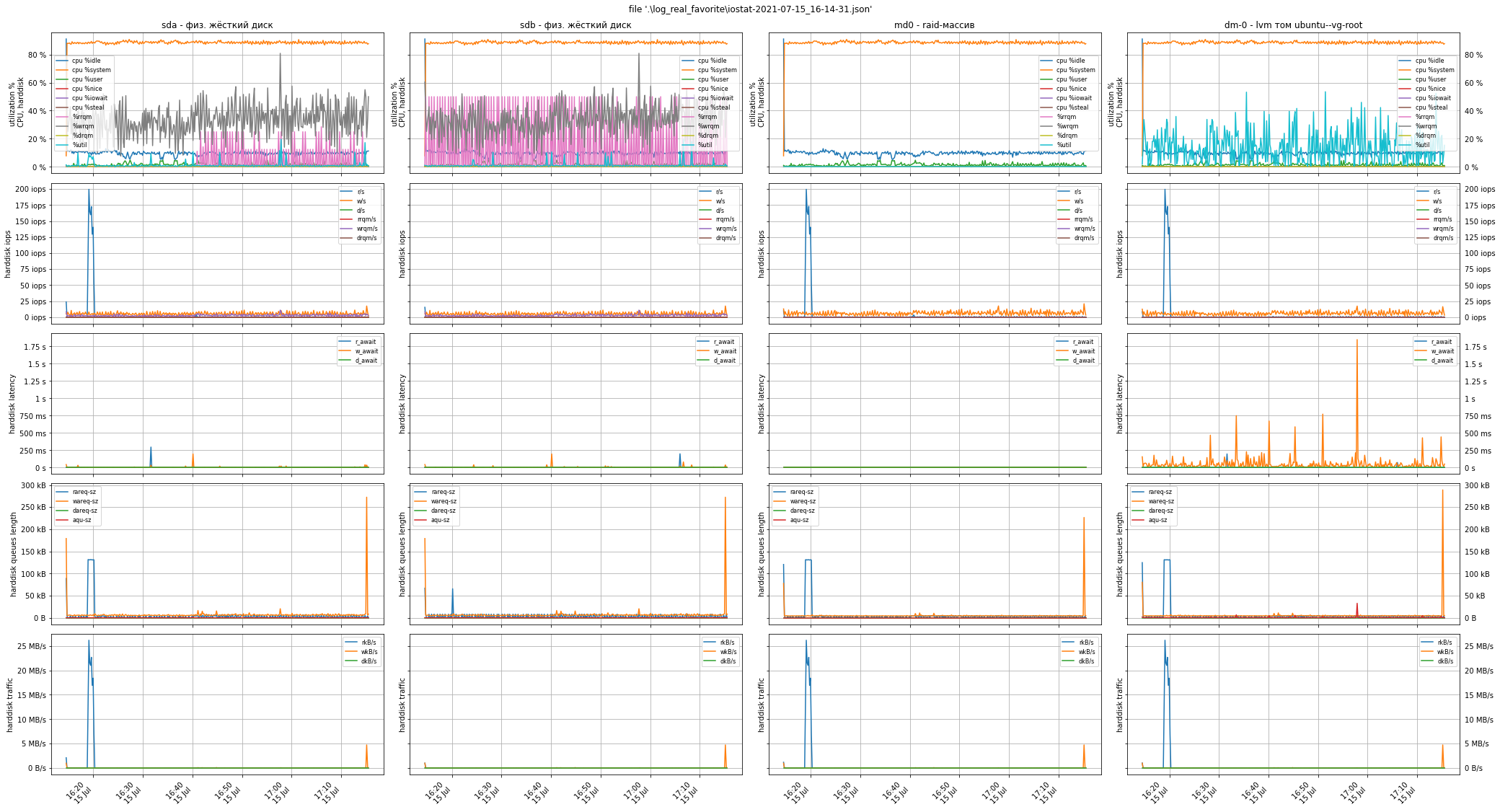
Помните, выше мы советовали вам обратить внимание на показатель Load Average и сделать скриншоты утилиты top или htop?! Смысл этого показателя, в пересчёте на одно процессорное ядро, следующий:
- la < 1 - у системы ещё есть свободные вычислительные ресурсы, очереди процессов на выполнение нет
- la = 1 - ресурсов уже нет, очереди пока ещё нет
- la > 1 - появилась очередь, в которой процессы ожидают освобождения ресурсов ЦПУ для своего исполнения
Хорошей практикой считается держать этот показатель в районе 0.7 - 0.8: с одной стороны ещё есть запас свободных ресурсов, с другой стороны - достаточно хорошая утилизация ЦПУ. В данном случае la = 80 / 32 = 2.5. Именно это и было причиной низкой производительности ПО: длина очереди ожидающих своего исполнения процессов в 1.5 раза превышала ту, что уже исполнялась на ЦПУ -> загрузка составила 250% -> ПО "тормозило".

Список полезных материалов
-
кратко о тротлинге при превышении лимита iops https://communities.vmware.com/t5/vSphere-Hypervisor-Discussions/After-apply-the-DISK-IOPS-limit-my-storage-latency-increased/m-p/1344871/highlight/true#M2945
-
статья VMWare о механизмах лимитирования https://core.vmware.com/blog/performance-metrics-when-using-iops-limits-vsan-what-you-need-know
-
официальная документация VMWare https://core.vmware.com/resource/vsan-operations-guide#sec6732-sub5
-
для чего нужны лимиты https://www.vmgu.ru/news/vmware-vsphere-virtual-disk-vmdk-iops-limit
-
презентация по алгоритму mClock - планировщик IO гипервизора, в т.ч. применительно к работе с хранилищами https://www.usenix.org/legacy/events/osdi10/tech/slides/gulati.pdf
-
статья "Как правильно мерять производительность диска" https://habr.com/ru/post/154235/
-
официальная документация
fiohttps://fio.readthedocs.io/en/latest/fio_man.html#fio-manpage -
официальная документация
iostathttp://sebastien.godard.pagesperso-orange.fr/man_iostat.html
