Основные преимущества использования NFS в Kubernetes
Использовать существующее хранилище, вы можете монтировать существующее тома данных, которые вы используете локально или в другом удаленном месте.
Совместное использование данных, благодаря тому, что тома NFS постоянные они могут использоваться для обмена данными между контейнерами, будь то в одном или разных POD.
Даже в случае сбоя сервера NFS, POD будут автоматически перезапускаться пока сервер NFS не восстановится, после чего продолжат свою работу. При этом мы все равно делаем резервные копии данных
Имеется возможность легко скопировать данные сервера NFS на другой сервер NFS и переключить их в случае критического сбоя
Когда приложение Kubernetes завершается, Kubernetes возвращает постоянный том и его заявку в пул. Данные из приложения остаются на томе. Его можно очистить вручную, войдя в виртуальную машину узла NFS и удалив файлы.
CSE может автоматически добавлять узлы NFS в конфигурацию Kubernetes при создании нового кластера. Администраторы кластера могут использовать узлы NFS для реализации статических постоянных томов, что, в свою очередь, позволяет развертывать приложения с сохранением состояния.
Presistent Volume
Статические presistent volume предварительно предоставляются администратором кластера. Они несут информацию о реальном хранилище, которое доступно для использования пользователями кластера. Они существуют в API Kubernetes и доступны для потребления. Пользователи могут выделить статический постоянный том, создав утверждение о постоянном томе, которое требует того же или меньшего объема памяти. CSE поддерживает статические тома, размещенные в NFS.
NFS Volume Архитектура
Том NFS позволяет монтировать существующий общий ресурс NFS (сетевая файловая система) в один или несколько pod. При удалении pods содержимое тома NFS сохраняется, а том просто отключается. Это означает, что том NFS может быть предварительно заполнен данными, и эти данные могут быть «переданы» между pod. NFS может монтироваться несколькими авторами одновременно.
Чтобы использовать тома NFS, нам нужен собственный сервер NFS с экспортированными общими ресурсами. CSE предоставляет команды для добавления предварительно настроенных серверов NFS в любой данный кластер. Следующая диаграмма показывает архитектуру реализации.
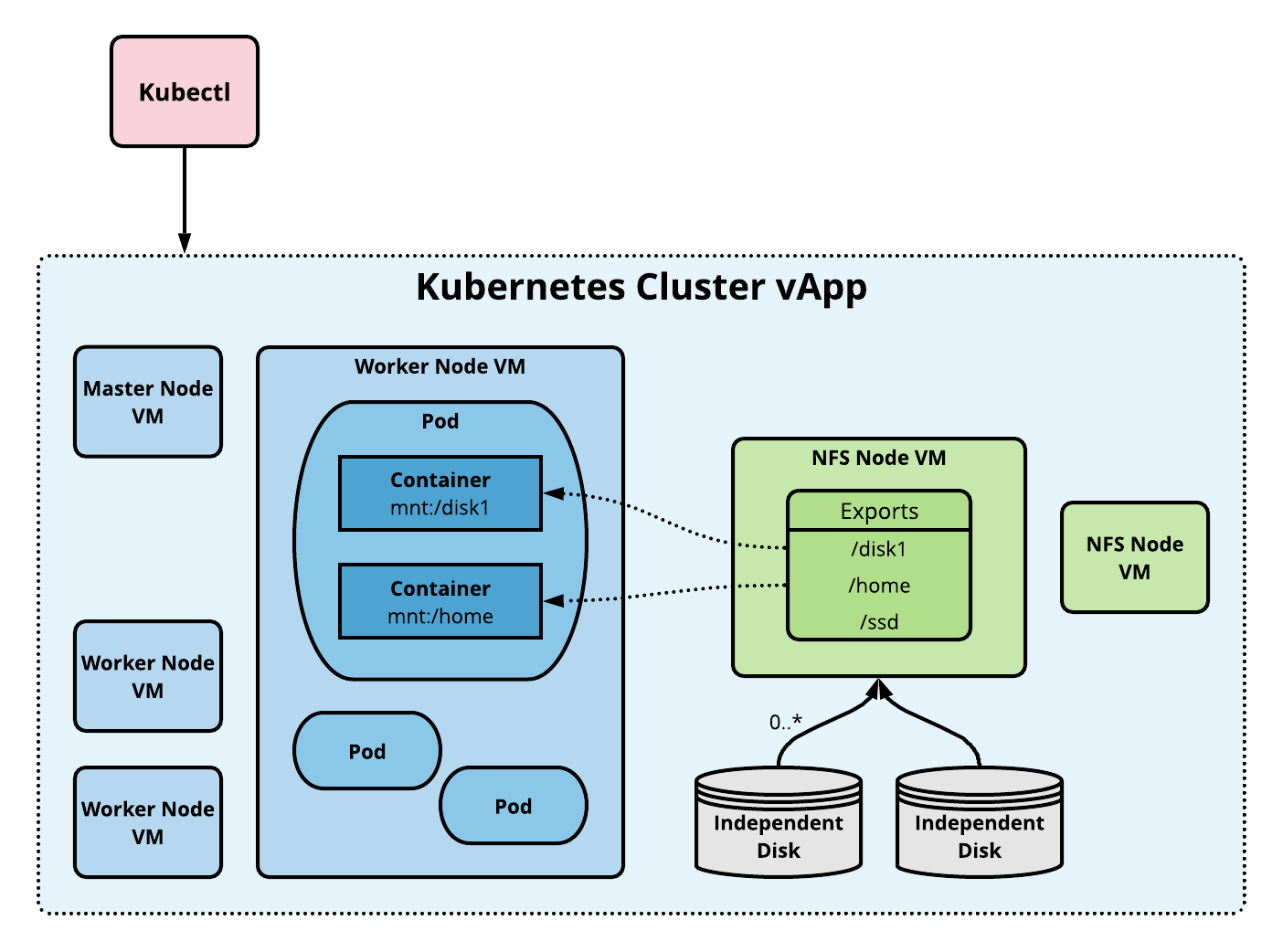
Создание кластера с присоединенным узлом NFS
Администрирование NFS начинается с создания кластера, где мы можем подготовить узел NFS. Давайте создадим кластер на основе Ubuntu, используя vcd cse cluster createкоманду, показанную ниже. Опция --enable-nfs сигнализирует CSE что он должен включать ноду NFS. Опция --ssh-key указывает, что наши ноды должны использовать SSH ключи пользователя. Ключ SSH необходим для входа на хост NFS и настройки общих ресурсов.
# Login.
vcd login cse.acme.com devops imanadmin --password='T0pS3cr3t'
# Create cluster with 2 worker nodes and NFS server node.
vcd cse cluster create mycluster --nodes 2 \
--network mynetwork -t ubuntu-16.04_k8-1.13_weave-2.3.0 -r 1 --enable-nfs \
--ssh-key ~/.ssh/id_rsa.pub
Эта операция займет несколько минут, пока расширение CSE создает приложение Kubernetes vApp.
Вы также можете добавить узел в существующий кластер с помощью команды, подобной следующей.
# Add an NFS server (node of type NFS).
vcd cse node create mycluster --nodes 1 --network mynetwork \
-t ubuntu-16.04_k8-1.13_weave-2.3.0 -r 1 --type nfsd
Настройка общих ресурсов NFS
Следующим шагом является создание общих ресурсов NFS, которые могут быть распределены через постоянные ресурсы тома. Во-первых, нам нужно добавить independent диск к узлу NFS, чтобы создать файловую систему, которую мы можем экспортировать.
# List the VMs in the vApp to find the NFS node. Look for a VM name that
# starts with 'nfsd-', e.g., 'nfsd-ljsn'. Note the VM name and IP address.
vcd vapp info mycluster
# Create a 100Gb independent disk and attach to the NFS VM.
vcd disk create nfs-shares-1 100g --description 'Kubernetes NFS shares'
vcd vapp attach mycluster nfsd-ljsn nfs-shares-1
Далее, ssh в самом хосте NFS.
ssh root@10.150.200.22
... (root prompt appears) ...
Разбейте и отформатируйте новый диск. В Ubuntu диск будет отображаться как / dev / sdb. Процедура ниже является примером; вы можете использовать любые удобные для вас способы.
root@nfsd-ljsn:~# parted /dev/sdb
(parted) mklabel gpt
Warning: The existing disk label on /dev/sdb will be destroyed and all data on
this disk will be lost. Do you want to continue?
Yes/No? yes
(parted) unit GB
(parted) mkpart primary 0 100
(parted) print
Model: VMware Virtual disk (scsi)
Disk /dev/sdb: 100GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 0.00GB 100GB 100GB primary
(parted) quit
root@nfsd-ljsn:~# mkfs -t ext4 /dev/sdb1
Creating filesystem with 24413696 4k blocks and 6111232 inodes
Filesystem UUID: 8622c0f5-4044-4ebf-95a5-0372256b34f0
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
Создайте точку монтирования, добавьте новый раздел в список файловых систем и смонтируйте его.
mkdir /export
echo '/dev/sdb1 /export ext4 defaults 0 0' >> /etc/fstab
mount -a
На этом этапе у вас должна быть работающая файловая система в каталоге / export. Последний шаг - создать каталоги и поделиться ими через NFS.
cd /export
mkdir vol1 vol2 vol3 vol4 vol5
vi /etc/exports
...Add following at end of file...
/export/vol1 *(rw,sync,no_root_squash,no_subtree_check)
/export/vol2 *(rw,sync,no_root_squash,no_subtree_check)
/export/vol3 *(rw,sync,no_root_squash,no_subtree_check)
/export/vol4 *(rw,sync,no_root_squash,no_subtree_check)
/export/vol5 *(rw,sync,no_root_squash,no_subtree_check)
...Save and quit
exportfs -r
Наша работа по подготовке общих файловых систем завершена. Вы можете выйти из узла NFS.
Использование постоянных томов Kubernetes
Чтобы использовать общие ресурсы, мы должны создать постоянные объемные ресурсы. Для начала давайте возьмем kubeconfig, чтобы мы могли получить доступ к новому кластеру Kubernetes.
vcd cse cluster config mycluster > mycluster.cfg
export KUBECONFIG=$PWD/mycluster.cfg
Создайте постоянный ресурс тома для общего ресурса в / export / vol1. Путь должен совпадать с именем экспорта, иначе вы получите ошибки, когда Kubernetes попытается смонтировать общий ресурс NFS в модуль.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-vol1
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
nfs:
# Same IP as the NFS host we ssh'ed to earlier.
server: 10.150.200.22
path: "/export/vol1"
EOF
Затем создайте заявку на постоянный том, соответствующую размеру постоянного тома.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 10Gi
EOF
Теперь мы запускаем приложение, которое использует постоянное требование объема. В этом примере выполняется busybox в нескольких модулях, которые записывают в общее хранилище.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ReplicationController
metadata:
name: nfs-busybox
spec:
replicas: 2
selector:
name: nfs-busybox
template:
metadata:
labels:
name: nfs-busybox
spec:
containers:
- image: busybox
command:
- sh
- -c
- 'while true; do date > /mnt/index.html; hostname >> /mnt/index.html; sleep $(($RANDOM % 5 + 5)); done'
imagePullPolicy: IfNotPresent
name: busybox
volumeMounts:
# name must match the volume name below
- name: nfs
mountPath: "/mnt"
volumes:
- name: nfs
persistentVolumeClaim:
claimName: nfs-pvc
EOF
Проверка работоспособности
Мы можем проверить состояние развернутого приложения и его хранилище. Сначала давайте позаботимся о том, чтобы все ресурсы были в рабочем состоянии.
kubectl get pv
kubectl get pvc
kubectl get rc
kubectl get pods
Теперь мы можем посмотреть на состояние хранилища, используя удобную kubectl execкоманду для запуска команды на одном из pod. (Замените правильное имя pod из вашего kubectl get podsвывода.)
$ kubectl exec -it nfs-busybox-gcnht cat /mnt/index.html
Fri Dec 28 00:16:08 UTC 2018
nfs-busybox-gcnht
Если вы выполнили предыдущую команду несколько раз, вы увидите дату и изменение хоста, когда модули записывают в файл index.html.
