Ensuring service availability to customers is a key IT challenge. It can be delivered at different levels:
- At the application level;
- At the virtual machine (VM) level;
- At the storage level.
In the following article, we will examine the scenarios for each of these.
1. APPLICATION LEVEL FAULT TOLERANCE
It is provided by an excessive number of computers in the group (nodes or nodes in the cluster), connected by communication channels and offered to the end user as a single service called a cluster. The only question is where to place these nodes. It is possible to locate them in a single data centre and eliminate problems related to technological maintenance and the technical failure of one of the nodes by transferring the active node from one host to another.
Or you can take a more comprehensive approach and place them in different datacenters, significantly reducing risks and increasing the number of factors against which the system is protected (storage, hypervisors, communication channels, geographic distribution). In the VMware vCloud Director infrastructure, this is achieved by connecting an additional virtual datacenter to the organisation. You can then select VDC in the cloud control panel.

Each VDC is independent. It allows you to create your vApp, independent networks, VMware vShield Edge and other virtual infrastructure objects. To do this, select the required VDC from the Datacenters tab in the Panel. The selected VDC appears at the top of the screen.

When you create a new vApp, you can always pre-select the correct VDC in which to place your virtual machines.

In the vCloud Director, the window title helps you identify the location of your vApp.

By creating your vApps in different datacenters and hosting virtual machine nodes there, you can provide application level resiliency for multiple services, such as this solution:
- Microsoft Exchange, using a Database Availability Group (DAG) cluster.
- Microsoft Active Directory, using the replication mechanism between domain controllers
- DFS
Microsoft SQL Server, using AlwaysOn technology (starting with MS SQL Server 2012), you can use secondary replicas, with the possibility of both synchronous (slow, with no data loss) and asynchronous (faster, with possible data loss) replication. For more details see:
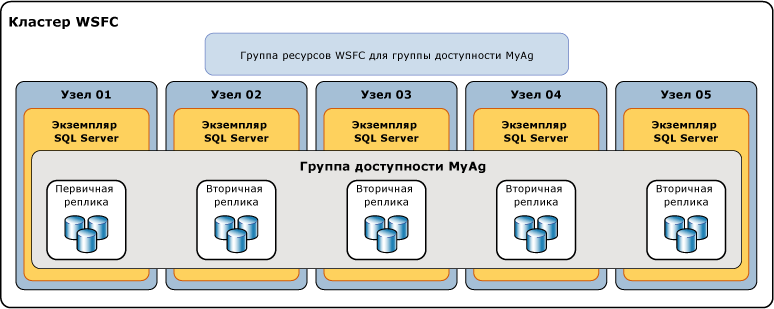
Network connectivity between virtual machines located in different data centres can be provided by
- By connecting VLANs between data centres, through additional service connections from Cloud4Y. This allows a single private network (grey addresses) between all VMs.
- Over public networks (Internet) by creating an additional VMware vShield Edge with a white IP address in the second datacentre and connecting over public IP addresses, or by creating a VPN channel between EDGEs over grey addresses. In this case, the grey subnets must be different in different datacenters.
Both options can be combined. On the one hand, you allow servers to connect directly without VPN. On the other hand, you provide two public points (white IP addresses) in different data centres to connect your users and provide a high availability service.
2. FAULT TOLERANCE AT VIRTUAL MACHINE LEVEL
To achieve the strategic goal of providing a highly available virtual machine, we recommend using Veeam Backup & Replication.
This technology uses replicas to create ready-to-run copies of the virtual machine in another data centre. Veeam replication accelerates disaster recovery, prevents data loss and ensures business continuity.
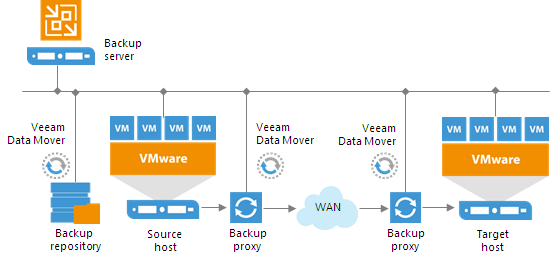
If the original machine in one datacenter fails for any reason, you can quickly switch to replication and restore business-critical services and applications in another datacenter with minimal downtime. For users, this happens quickly, allowing them to continue working while IT staff troubleshoot the 'problem' data centre.
The virtual machine replica is created by creating replication tasks with a certain frequency. During the first session of the replication task, Veeam Backup & Replication copies the entire VM image and registers a copy of the VM on the target ESX(i) host. In subsequent sessions, Veeam Backup & Replication copies only the data blocks of the VM that have changed since the last session (incremental changes) and creates a new recovery point for replication of the VM.
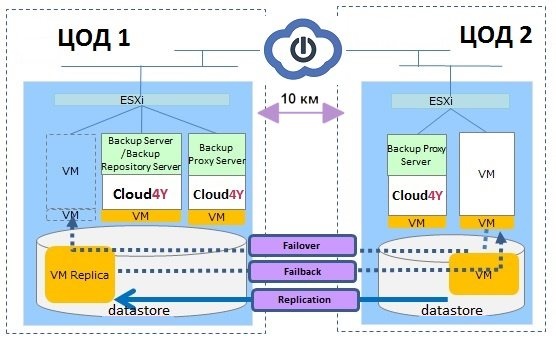
This recovery point allows you to roll back the virtual machine to the required state. We recommend that you support multiple recovery points to ensure that your replica remains functional. If the last recovery point fails, you can use an earlier recovery point.
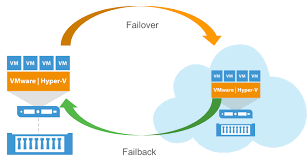
Once the problem is resolved in one of the datacenters, you can switch from the replica back to the original virtual machine or continue to use the replica as a working VM.
3. FAULT TOLERANCE AT THE DATA STORAGE SYSTEM (DSS) LEVEL
For customers with specific disaster tolerance requirements, we offer a SyncCluster solution that provides high fault tolerance and service availability.
SyncCluster is a unique service that combines a cluster-based array with synchronous mirroring.

A data storage system is implemented with half of the system located in a tertiary data center and the other half located 10km away in another tertiary data center. Both halves operate synchronously as a single structure. This approach ensures that data is written to both stores. In the event of a failure in one of the data centres (power failure, failure of any part of the storage system, failure of controllers, failure of several disks in a disk group in a short period of time, failure of communication channels between the data centres), your data remains available (RPO=0, RTO=10 minutes), i.e. no transaction is lost.
If in the previous solution replication was performed at VM level and with certain periods, synchronous replication is performed at storage level all the time, avoiding unnecessary load on servers, ensuring maximum SLA of 99.99% and preserving data. This solution is particularly suitable for software that does not support application level replication.
SyncCluster is a cost-effective solution that ensures continuous availability of services and data for companies where business continuity is critical.
